
Contents
pandasとは
Pythonにはpandasというライブラリがあります。
pandasはウェス・マッキニー氏によって作られました。
投資運用会社に在籍していたマッキニー氏は自身の業務を効率化するためにpandasを生み出しました。
データの整形や、欠損値、時系列データの扱いなど、実用的な機能が備わっています。
pandasはNumPyをベースに作成されていて、NumPyを使って作成したデータをシームレスに扱うことができます。
この記事ではpandasの基本操作を入門者向けに書いていきます。
JupyterNotebookを使う方法
pandasを使うときは、JupyterNotebookというプログラムを実行できるツールを使用すると、快適に作業を進められます。
Macでターミナルを開き、次のように入力するとJupyterNotebookがブラウザで開きます。
user@computer$ jupyter notebookブラウザが立ち上がり次のように表示されます。

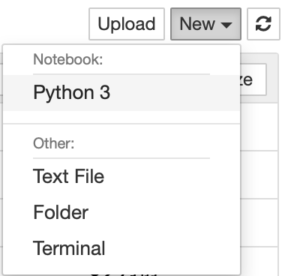
右上のNewからPython3を選択してください。
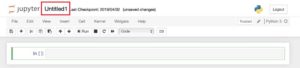
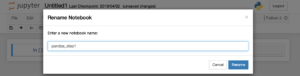
ノートが開いたらUntitleというファイル名になりますので、その部分をダブルクリックしてタイトルを変更しておきましょう。
ここでは、pandas_step1というタイトルにしました。
JupyterNotebookにプログラムを書き込む
それでは準備ができましたの、実際にプログラムを書いて実行しましょう。
JupyterNotebookでは、枠の中にプログラムを記述して、Runボタンまたは、Shift+Enterで実行します。
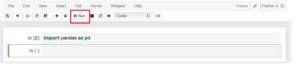
まずはpandasをインポートします。

実行されると、新しい枠が表示されます。
プログラムがエラーを起こす場合は、枠の下にエラーメッセージが表示されます。
枠を削除することができます。
枠を選択した状態でハサミボタンをクリックすると、枠が削除されます。

pandasのデータ構造Series
pandasには、シリーズ(Series)と(DataFrame)という2つのデータ構造が存在します。
シリーズは1次元の配列のようなオブジェクトです。
エクセルで例えると1行に存在するセル群です。
series_obj = pd.Series([1, 2, 3, 4]) series_obj
Shift+Enterを押すとプログラムが実行され、次のように結果が表示されます。
0 1 1 2 2 3 3 4 dtype: int64
データにindexをつけてみましょう。
0、1、2、3をa、b、c、dに変更します。
series_obj = pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd']) series_obj
次のように変更されました。
a 1 b 2 c 3 d 4 dtype: int64
特定の値を選択してみましょう。
エクセルで言うと、特定のセルの値を選択すると言うことになります。
indexを指定することで、特定の値のみ抽出することができます。
series_obj['a']
次のようにaに存在する1が結果として表示されました。
1
複数の値を選択するときは、次のように羅列して書きます。
[ [ ] ]このように四角括弧を二重にする必要があります。
series_obj[['b', 'c', 'd']]
次のように複数の値の結果が返りました。
b 2 c 3 d 4 dtype: int64
ちなみにdtype: int64と表示されているのは、データの型がint型ですよ、と教えているのです。
pandasで辞書型のデータを扱う
pandasでは、辞書型のデータも取り扱うことができます。
dic_data = {'Tokyo': 123, 'Kyoto': 234, 'Hokkaido': 345}
dic_data
次のように結果が返されます。
{'Tokyo': 123, 'Kyoto': 234, 'Hokkaido': 345}
見づらいので、縦並びに変更します。
dic_obj = pd.Series(dic_data) dic_obj
次のように縦並びに変わりました。
Hokkaido 345 Kyoto 234 Tokyo 123 dtype: int64
pandasのデータ構造DataFrame
データフレームはテーブル形式のスプレッドシート風のデータ構造を持っています。
エクセルで言うと、1枚のシートです。行と列両方を持っています。
それではデータフレーム型のデータを作成します。
dataframe_obj = {'year': [2008, 2012, 2016, 2020],
'city': ['Beijing', 'London', 'Rio de Janeiro', 'Tokyo'],
'event': [302, 302, 306, 339]}
dataframe_obj
実行すると次の結果が返ります。
{'year': [2008, 2012, 2016, 2020],
'city': ['Beijing', 'London', 'Rio de Janeiro', 'Tokyo'],
'event': [302, 302, 306, 339]}
見づらいので整形します。
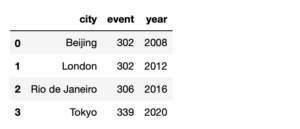
frame = pd.DataFrame(dataframe_obj) frame
下記のように見やすく表示されました。
データフレームのindexを変更
indexの表記を変更してみます。
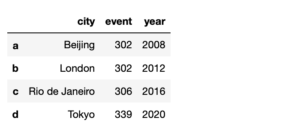
frame2 = pd.DataFrame(dataframe_obj, index=['a', 'b', 'c', 'd']) frame2
次のようにindexが変わりました。
cityという列の値だけを抽出してみます。
frame2.city
これだけで、次のように抽出されます。
a Beijing b London c Rio de Janeiro d Tokyo Name: city, dtype: object
ixフィールドを使う
ixというインデックス参照をするためのフィールドを使って、行位置やname属性を指定して値を抽出できます。
エクセルに置き換えて言うと、行の情報を取り出しています。
frame2.ix['d']
次のように結果が返ります。
city Tokyo event 339 year 2020 Name: d, dtype: object
DataFrameの列を値とともに追加する
項目をまとめて追加することができます。
エクセルで言うと、列を追加しています。
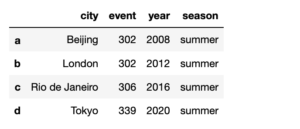
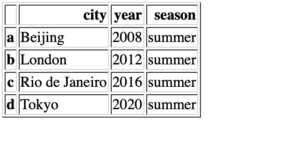
frame2['season']='summer' frame2
結果はご覧の通りです。
データフレームの値を削除
データフレームの行を削除してみます。
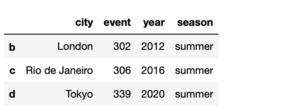
frame3 = frame2.drop('a')
frame3
次のようにindexがaの列が削除されました。
データフレームの列を削除してみます。
frame4 = frame3.drop('event', axis=1)
frame4
次のようにeventの列が削除されます。

データフレームに行を追加
データフレームに行を追加してみます。
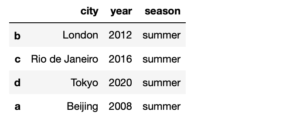
frame4.loc['a'] =['Beijing', 2008, 'summer'] frame4
次のように追加されました。
インデックス値でソート
aが一番下にありますので、順番に並び替えます。
frame4.sort_index()
次のように並び変わりました。

pandasのデータをファイル形式を指定して書き出し
pandasで作成したデータは、ファイルとして書き出すことができます。
frame4をframe5に保存します。
frame5 = frame4.sort_index() frame5
ファイル名を指定して書き出します。
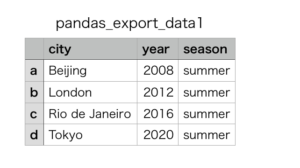
export_data = frame5.to_csv('pandas_export_data1.csv')
次のファイルが書き出されました。
pandasデータをhtmlファイルとして書きだす
pandasで作成したデータをhtmlファイルにすることができます。
export_data2 = frame5.to_html('pandas_export_data2.html')
次のファイルが作成されました。
まとめ
pandasを使うと様々なデータの作成、ファイルの読み込み・書き出しを行えます。
ファイルの読み込みについては、また別の機会に記事にしたいと思います。
最後までお読みいただきありがとうございました。