今回はpandasを使って、Googleスプレッドシートを集計します。
この記事では、pandasでGoogleスプレッドシートを読み込む方法、家計簿の月別の集計方法などを書いていきます。

Contents
元データの構造の確認
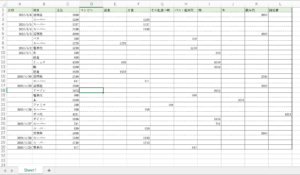
家計簿は、次のようなデータ構造になっています。
一番左の列が日付です。
支出の列に金額があり、さらに項目の列(コンビニ、昼食…)にも同じ金額を入力しています。

データの前処理の必要性
このデータについて、pandasで月毎の支出を集計したいのですが、日付の列に空白のセルがある為、このままですと月毎の支出を計算できません。
Googleスプレッド上で、空白の日付データを入力すれば済みますが、家計簿データの行数が1000行あった場合は、大変な作業になってしまいます。
そういった時にpandasやPythonを使うと便利です。
ここからは、JupyterNotebookを使用しますので、あらかじめインストールをしてください。
基本操作についてはこちらの記事をご覧ください。
Googleスプレッドシートをpandasで読み込む方法
Googleスプレッドシートをダウンロードして、JupyterNotebookのファイルが作成されるディレクトリと同じディレクトリに、置いてください。
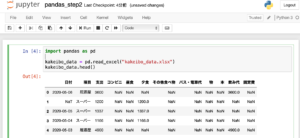
JupyterNotebookで次のように入力して、先頭の5行を表示させます。
import pandas as pd
kakeibo_data = pd.read_excel("kakeibo_data.xlsx", dtype = 'object')
kakeibo_data.head()
次のような結果が表示されます。

読み込んだデータの型を確認しておきます。
kakeibo_data.dtypes
結果は次の通りです。
日付 datetime64[ns] 項目 object 支出 int64 コンビニ float64 昼食 float64 夕食 float64 その他食べ物 float64 バス・電車代 float64 物 float64 本 float64 飲み代 float64 固定費 float64 dtype: object
日付列は日付型、支出列は数値型になっていることを確認できました。
項目列は、文字型になっています。pandasでは、文字列型が object と表記されます。
Pythonで言う str です。
データの前処理
日付列の空白を埋める作業を次のコードで行います。
for i in range(len(kakeibo_data["日付"])):
if kakeibo_data["日付"].iloc[i] is pd.NaT:
kakeibo_data["日付"].iloc[i] = kakeibo_data["日付"].iloc[i -1]
print(kakeibo_data["日付"].iloc[i])
結果は次のようになりました。
print文で、追記した日付を表示させています。
2020-05-06 00:00:00 2020-05-03 00:00:00 2020-05-03 00:00:00 2020-05-01 00:00:00 2020-05-01 00:00:00 2020-05-01 00:00:00 2020-05-01 00:00:00 2020-04-30 00:00:00 2020-04-29 00:00:00 2020-04-29 00:00:00 2020-04-29 00:00:00 2020-04-29 00:00:00 2020-04-28 00:00:00 2020-04-28 00:00:00 2020-04-27 00:00:00 2020-04-27 00:00:00
Warningは無視して大丈夫です。
プログラムの解説
for i in range(len(kakeibo_data[“日付”])): で、日付列の行数文、forで回す設定をしています。
is pd.NaT でデータがNull値かどうかを確認しています。
kakeibo_data[“日付”].iloc[i] = kakeibo_data[“日付”].iloc[i -1] で、1つしたの行の日付をコピーしています。
データの前処理その2
月別に合計する為の準備をします。
新しい列「年月」を作成して、年と月の組み合わせの日付型をつくります。
kakeibo_data["年月"] = kakeibo_data["日付"].dt.strftime("%Y%m")
kakeibo_data.head()
次のように固定費列の右に列が増えました。


groupbyを使ってsumで集計する
月別の支出合計を計算します。
tukibetu = kakeibo_data.groupby("年月").sum()["支出"]
print(tukibetu)
結果は次のようになります。
4月の支出が、29,020円
5月の支出が、27,215円と言う集計結果が返りました。
年月 202004 29020 202005 27215 Name: 支出, dtype: int64
前処理について
ここでは、日付が文字列型になっているデータを扱う際の話を付け加えておきます。
データ型が適切でないとエラーが発生するケースがあります。
test_dataと言うファイルがあったとします。
文字列型の日付を日付型へ変換するには、次の前処理を行います。
test_data['日付']=pd.to_datetime(test_data['日付'], errors='coerce')
pd.to_datetime で、日付型へ変換しています。
まとめ
今回はGoogleスプレッドシートの家計簿データ支出をpandasで、月毎に集計する方法をご紹介しました。
最後までお読みいただきありがとうございました。