プログラミングにおいて、正規表現とは、文字列のパターンマッチングです。
実際にプログラムを見てみましょう。

Contents
正規表現によるパターンマッチ
Pythonで正規表現を使用する際は、reモジュールをインポートします。
import re
s = "Simple is better than complex."
match = re.findall("Simple", s)
print(match)
re.finadallで、変数 s の中に、Simple という文字列があるかどうかを検索しています。
プログラムの実行結果は、次の通りです。
Simpleという文字列がマッチしたので、返されました。
['Simple']
正規表現で大文字と小文字を無視する
先ほどのプログラムでは、Simple をsimple にすると、パターンマッチが行われません。
正規表現で大文字と小文字の違いを無視するには、引数に re. IGNORECASEフラグを記述します。
コードは次のように変わります。
import re
s = "Simple is better than complex."
match = re.findall("simple", s, re.IGNORECASE)
print(match)
結果は先程と同じです。
三重引用符で複数行の文字列を記述する方法
三重引用符( “”” “”” )を使うと、複数行の文字列を記述することができます。
s = """Beautiful is better than ugly. Explicit is better than implicit. Simple is better than complex. Complex is better than complicated. Flat is better than nested. Sparse is better than dense. Readability counts. Special cases aren't special enough to break the rules. Although practicality beats purity. Errors should never pass silently. Unless explicitly silenced. In the face of ambiguity, refuse the temptation to guess. There should be one-- and preferably only one --obvious way to do it. Although that way may not be obvious at first unless you're Dutch. Now is better than never. Although never is often better than *right* now. If the implementation is hard to explain, it's a bad idea. If the implementation is easy to explain, it may be a good idea. Namespaces are one honking great idea -- let's do more of those!""" print(s)
複数行から文字列を検索
複数行の文字列から検索するときは、 findall関数の引数に、 re. MULTILINE を記述します。
If を検索してみます。
import re
s = """Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!"""
match = re.findall("If", s, re.MULTILINE)
print(match)
結果は次の通りです。
['If', 'If']
findall関数を使ってbetterという単語を検索してみます。
import re
s = """Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!"""
match = re.findall("better", s, re.MULTILINE)
print(match)
結果は、betterが8つ返されました。
['better', 'better', 'better', 'better', 'better', 'better', 'better', 'better']
行の先頭の文字列がマッチするか検索する方法
正規表現で、キャレット( ^ ) を使用すると、行の先頭の文字列と一致するかを検索できます。
match = re.findall("^better", s, re.MULTILINE)
このように better の前に、キャレットをつけて ^better とすると、プログラムの結果は、次のように better は見つからなかった、となります。
[]
Now という文字列にキャレット( ^ )をつけて検索すると、Nowは行の先頭にある文字列なので、Nowという結果が返ります。
match = re.findall("^Now", s, re.MULTILINE)
結果
['Now']
どんな文字にもパターンマッチするピリオド
正規表現でピリオド( . ) を使うと、どんな文字にも一致します。
i に続く文字が、どんな文字でも良いから検索するという設定で検索してみます。
match = re.findall("i.", s, re.MULTILINE)
結果は次のようになります。
['if', 'is', 'ic', 'it', 'is', 'im', 'ic', 'it', 'im', 'is', 'is', 'ic', 'is', 'is', 'il', 'it', 'ia', 'ia', 'ic', 'it', 'it', 'il', 'ic', 'it', 'il', 'ig', 'it', 'io', 'io', 'it', 'io', 'ir', 'is', 'is', 'ig', 'im', 'io', 'is', 'in', 'it', 'id', 'im', 'io', 'is', 'in', 'it', 'id', 'in', 'id']
行の最後の文字を指定して検索する方法
正規表現で、$ を使用すると、行の最後の文字を指定して検索することができます。
英文なので、行の最後は全てピリオドです。
次の記述は、先ほどの「どんな文字にもマッチするピリオド」とは異なりますので、ご注意ください。
match = re.findall("idea.$", s, re.MULTILINE)
結果は次のようになります。
['idea.', 'idea.']
正規表現で数字を検索する方法
正規表現で数字を検索するときには、\d を記述します。
変数sに入れる文章に数字を加えました。
import re
s = """Beautiful is better than ugly.
123
Explicit is better than implicit.
10000
Simple is better than complex.
5678
"""
match = re.findall("\d", s, re.MULTILINE)
print(match)
結果は次のようになります。
['1', '2', '3', '1', '0', '0', '0', '0', '5', '6', '7', '8']
正規表現パターンを繰り返す方法
アスタリスク ( * ) を使用すると、正規表現パターンを繰り返すことができます。
直前のパターンが0回以上一致する文字列を返します。
import re
s = """
aaa
aab
abb
bbb"""
match = re.findall("aa*", s, re.MULTILINE)
print(match)
結果は次のようになりました。
['aaa', 'aa', 'a']
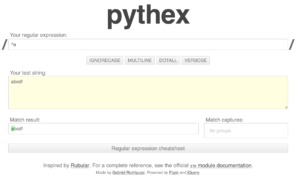
簡単に正規表現パターンを見つける方法
ここまでで、「正規表現難しい」と思った方に朗報があります。
次のサイトを利用すれば、自分が意図する正規表現になるまで、色々と正規表現パターンを試すことができます。
https://pythex.orgというサイトです。
使い方:
- 2ブロック目の Your test string: に、文字列をコピペします。
- 1ブロック目の Your regular expression: に、自分で考えた正規表現を入力します。
- 指定した正規表現の対象文字列に、自動で色が塗られます。

まとめ
正規表現は使いこなせるようになるまでが難しいです。
使いこなせるようになると、とても楽な方法であることを認識できます。
最後までお読みいただきありがとうございました。